今天周末,想学点东西,看到直接学php网站上面的思维导图,想下载下来,有空时候看一下,可是都是一个链接然后点开里面到文章内容,里面有一张图和介绍。所以几十张图片慢慢这样下载有点麻烦。于是想用python直接爬下就好了。
我电脑安装的是python3,所以直接用这个版本写一个程序抓取吧。
首先是导入一下必要的组件库,用来请求、抓取、下载等。
代码可以实现简单的爬取了,不过有些网站需要添加代理、伪装、多线程等。还有其他的优化设计。
import urllib.request
import re
import os
import urllib
#抓取a链接所在的页面,返回源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
#从html里面匹配图片标签进行下载
def getImg(html,path):
reg = r"src='(.+?\.png)'" #写一个匹配规则
imgre = re.compile(reg)
imglist = imgre.findall(html)#从页面匹配规则,抓取图片
if not os.path.isdir(path):#如果没有保存文件夹则创建
os.makedirs(path)
#遍历页面所有的图片标签,保存的文件名称为抓取到的文件名称
#x = 0
#for imgurl in imglist:#我的只需要一张图片,就不需要循环了,多张的话启用我这个循环即可
urllib.request.urlretrieve('https://www.xxxx.com'+str(imglist[0]),path+os.path.basename(imglist[0]))
# x = x + 1
return imglist[0]
linkUrl='http://www.xxx.com/xxxx/xxx/'
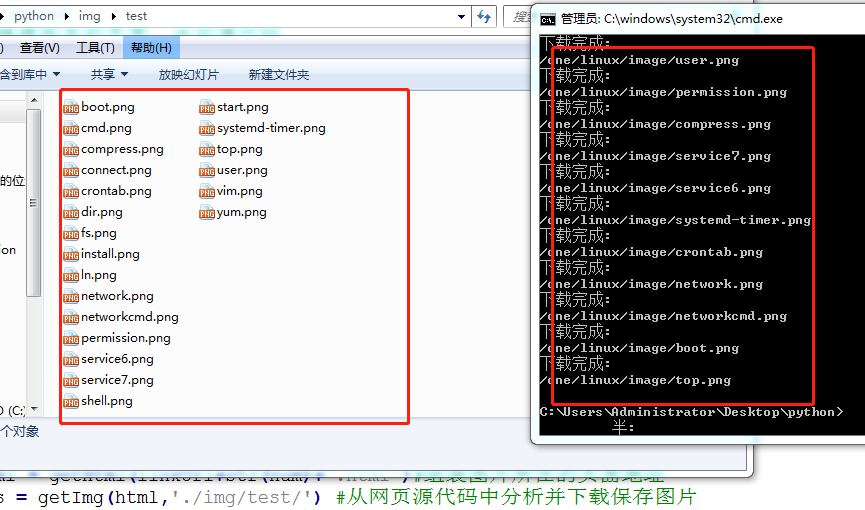
for num in range(232,253):#需要抓取的页面做一个循环,依次抓取
html = getHtml(linkUrl+str(num)+'.html')#组装图片所在的页面地址
res = getImg(html,'./img/test/') #从网页源代码中分析并下载保存图片
print('下载完成:')#打印下载的结果
print(res)
顺手把录音介绍下载了: